Python 라이브러리를 활용한 인공지능
라이언의 꿀팁백과
1 개요
올해는 머신러닝 쪽 관련 지식을 함양하고자 한다. 이러한 노력의 일환으로 회사에서 보내주는 외부연수로 아래 강의를 수강했다.
| 강좌명 | 교육기간 | 교육장소 | 기타 |
|---|---|---|---|
| Python 라이브러리를 활용한 인공지능 | 2022.8.8 ~ 2022.8.12 | 한국생산성본부 8층 803호 | - 강사명 : 박성백 (sungback@naver.com / 010-8711-7982) ← 평생 A/S 가능
- 수강자 : 10명 (오프라인 7명, 온라인 3명) - 교 재 : <Hands-On Machine Learning with Scikit-Learn Keras & TensorFlow> |
2 교육과정
이번에 내가 수강하는 과정은 아래와 같이 총 5일, 35시간 동안 머신러닝 중 딥러닝에 대해 학습하는 과정이다.



3 책
도서를 읽으며 학습한 내용은 별도 페이지인 핸즈온 머신러닝(2판)(책)을 참고하자.
4 강의
총 5일 동안 교육한 내용을 아래에 간략히 정리했다.
4.1 1일차
- 인공지능 관련 지루한 설명을 들었다.
- 파일 공유를 위한 주소(https://tinyurl.com/ai220808)를 공유 받았다.
- 인공지능 공식을 간략히 소개하면 y=Wx 의 행렬곱이다.
- W 는 가중치(weight)를 의미한다.
- 강사님이 딥러닝은 인간의 뇌를 모방했다면서 "유재석" 얘기를 했는데 앞에 앉아 있는 어떤 학생이 유재석이 나오는 <유퀴즈 온 더 블록>을 보고 있어서 어이 없었다.
- 이 수업에서는 파이썬 언어, 수집(BeautiflSoup), 분석(Pandas), 시각화(Matplolib, Seaborn), ML 까지 실습을 하며 이를 위해 아나콘다(Anaconda)를 설치하며, 실습은 함께 설치하는 주피터(Jupyter)를 활용.
- 환경설정은 아래와 같이 함
- Anaconda 다운로드 https://www.anaconda.com/products/distribution
- 설치
- 주피터 노트북 실행
- 주피터 노트북에 CSS를 적용하려면 윈도우 10 기준으로 %HOMEPATH% 에 .jupyter 폴더를 만든 후, 이어서 방금 만든 폴더 안에 custom 폴더를 만든다. 이어서 custom.css 라는 파일로 아래 CSS 파일을 custom 폴더에 저장한다. 그런 후 주피터 노트북을 재실행하면 CSS가 적용된다.

.container { width:100% !important; }
.CodeMirror {font-family: D2Coding; font-size: 22pt; line-height: 140%;}
div.output {
font-family: D2Coding;
font-size: 12pt;
}
div.prompt {
padding-left: 0;
min-width: 2ex;
}
- D2Coding 폰트를 설치했다. (https://github.com/naver/d2codingfont)
- 시험 공지를 해줬다. 4지선다 15문제, 단답형 5문제로 총 20문제다.
- (시험) 머신러닝 학습 특성에 따른 분류 : Supervised, Unsupervised, Reinforcement Learning
- 주피터에서 파이썬 자료형, 제어문 등 기본 문법을 실습했다.
4.2 2일차
- 오늘은 버스가 많이 막혀서 9:28 에 도착했다. 도착하기 전에 전화를 주셔서 "도착했어요!" 라고 얘기했다. KCP 수업 담당자님께서 강사님이 교통 체증으로 늦어서 양해의 표현으로 커피를 샀으니 마시라고 하셨다. 하하하. 그런데 강사님이 내가 도착한 후 1분 뒤에 오셨다. 강사님이 매번 늦어서 커피가 매번 제공되면 좋겠다.
- 어제 학습한 내용을 복습했다.
- 주피터 노트북에서 모든 명령어를 다시 실행하려면 Kernel 메뉴에 있는 Restart & Run All 을 실행한다.
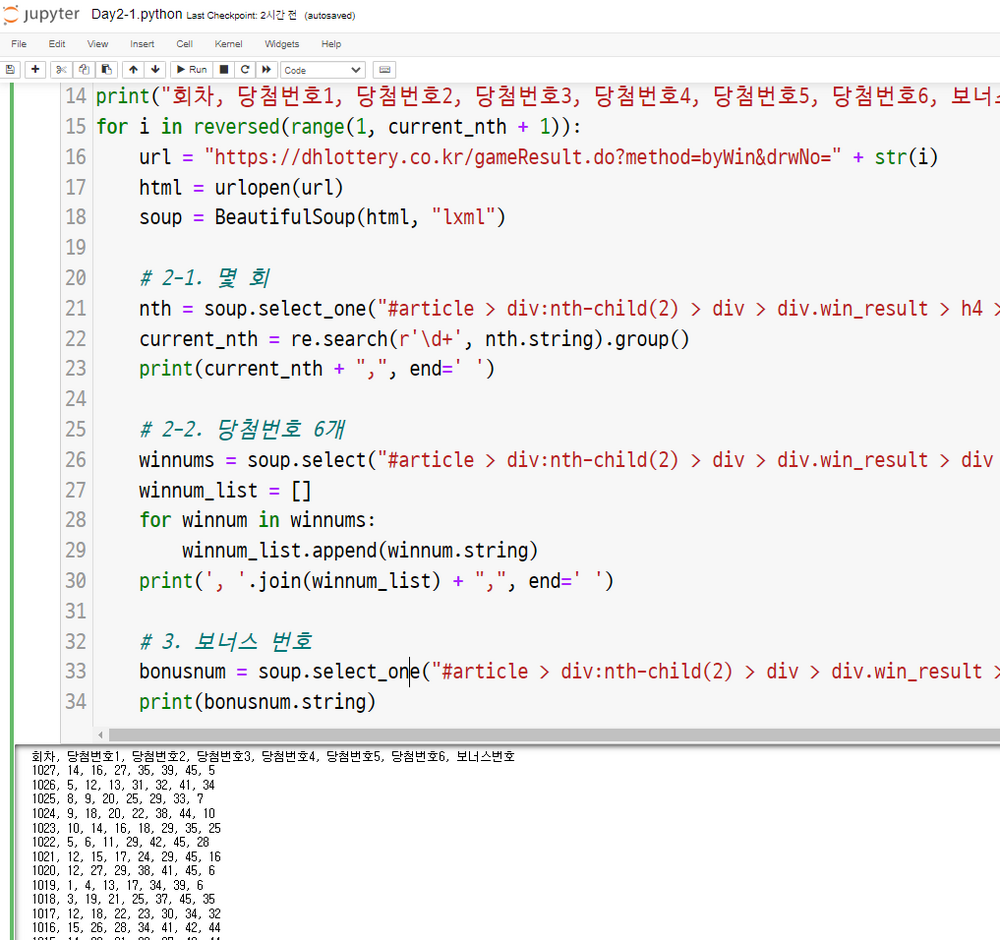
- 저 강사님 수업을 아마도 3년 전에 다른 수업에서 들었던 것 같다. 과거에 했던 로또 당첨번호 웹 스크래핑 실습을 또 한다. 사골국물도 아니고 이게 뭔가요?!?!?! ㅠ.ㅠ
- 아무튼 나는 현재까지 당첨된 로또 번호 및 보너스 번호를 출력하는 프로그램으로 개량했다. (3년 전에도 똑같은 걸 했었다 ㅎ.ㅎ)


- 이어서 타이타닉 호 승객 생존 예측 미니 프로젝트를 하는데 이것도 아마 3년 전에 했던 것 같다.
- 파이썬 라이브러리 Numpy는 수치연산을 매우 빠르게 하는데 이것이 가능한 이유는 내부 코드를 C/C++로 구현했기 때문이다.
- 코로나 이전에 기상청 직원이 강의를 수강했는데 거기는 여전히 포트란(Fortran)을 사용하고 있다고 한다. 다만 이를 Python에서 사용할 수 있게 바인딩해서 사용을 하고 있다고 한다.
- 점심시간 전에 <타이타닉 호 승객 생존 예측 미니 프로젝트>를 위한 사전 작업을 완료했다. (데이터 제공, 가설 수립 등)
- 커피 사주셨다. 나 퀴즈 틀렸는데? ㅋㅋㅋㅋㅋㅋㅋㅋ 위로커피인듯...
- Dataframe의 info() 함수 결과값에서서 중요하게 봐야 하는 것 중 하나는 Non-Null Column 개수로 결측치 정도를 확인해야 한다. 이 값에 다라 해당 데이터를 활용할 수 있을지 없을지가 결정되기 때문이다.
- 데이터 타입은 아래와 같이 나뉨
- 수치형
- 이산형 : 정수
- 연속형 : 실수
- 범주형
- 명목형 : 혈액형
- 순서형 : 학점, 성적
- 수치형
- Pandas의 Dataframe을 통해 데이터를 조작하는 것은 정말 사기다. 안 쓸 수 없다.
- 원-핫 인코딩(One-Hot Encoding)은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식입니다. 이렇게 표현된 벡터를 원-핫 벡터(One-Hot vector)라고 함 (링크)
- 결측치를 채우는 방법을 배움
4.3 3일차
4.3.1 2일차 복습
- iPhyon 노트북은 서로 독립적이기 때문에 매번 import 문 등을 동일하게 추가해야 한다.
- Pandas의 static member function을 통해 엑셀파일을 읽을 수 있다. (C++, Java와 같은 언어에서는 인스턴스가 아닌 객체명으로 멤버를 호출했으니 정적 멤버함수가 맞는데 파이썬에서도 동일한가? 알아봐야할듯)
- df = pd.read_excel("파일명")
- 타이타닉 데이터 분석에서 파일을 연 후에 가장 먼저 한 행동은 특성 탐색
- 머신러닝을 활용하려면 입력과 출력이 반드시 숫자가 되어야 함 (예: 알파벳을 이해하려면 대소문자 알파벳 52자를 숫자로 변환한 후 학습을 시켜야 함)
- Dataframe 에서 교차표는 crosstab 함수로 그리며 합계를 추가하려면 margins=True 를 작성
- 데이터를 범주형으로 만들려면 Dataframe의 cut 함수 사용
- df['age_cat'] = pd.cut(df['age'], bins=[0,10,20,50,80], include_lowest=True, labels=['baby', 'teenage', 'adult', 'old'])
- Pandas에서 데이터를 반환하는 게 아니라 호출한 객체 값이 저장하게 하려면 inplace=True 를 추가하면 됨 (항상 그렇다는 건 아님)
- 현실에 맞게 학습하려면 이상치를 포함하는 게 맞음
- df[df['fare'].isnull()] : 운임이 null(결측치)인 사람 찾기
- df['survived'].value_counts() : 생존자 수 카운트
4.3.2 머신러닝 코딩 5단계
- 훈련 데이터와 테스트 데이터를 나눈다. : train_test_split
- ML 알고리즘 선택
- 머신러닝 알고리즘은 수학
- 훈련 : fit
- 평가 : score
- 새 데이터로 예측 : predict
4.3.3 수업내용 필기
- Tree를 여러 개 가져다가 다수결로 결정하는 알고리즘을 앙상블(Ensemble) 이라고 합니다.
- train_test_split 함수를 통해 학습 데이터와 테스트 데이터를 나눌 수 있는데, 이 때 random_state 값을 설정해야 하이퍼파라메터 조정을 하는 데 애로사항이 없다.
- 머신러닝이 최종적으로 하는 일은 두 가지로 나눌 수 있음 → 분류를 잘하거나 값을 맞추거나
- DecisionTreeClassifier : 분류
- DecisionTreeRegression : 값
- 대부분의 머신러닝 알고리즘 함수에는 -Classifier 또는 -Regression 이 붙음
4.4 4일차
업데이트 예정
4.5 5일차
업데이트 예정
5 참고자료
- 정오표 https://tensorflow.blog/handson-ml2/
- 유튜브 강의 https://bit.ly/homl2-youtube/
- GitHub Repository https://github.com/rickiepark/handson-ml2
- FMA: A Dataset For Music Analysis https://github.com/mdeff/fma
- 딥 러닝을 이용한 자연어 처리 입문 https://wikidocs.net/book/2155